「駆け出しの翻訳屋」として、学習したことをちょこちょこ書くつもりでしたが、「いつまで駆け出しなんだ?!」と言っているうちに早、リタイア年齢に!
現在は、城めぐり、乗り鉄などの旅と読書の話がメインです。
用語集の変換の話で、Excel のセル内にタブや改行があると変換が失敗すると書いたのですが、実際にこれらを検索するのは結構むずかしいように思います。^^;
普通、Excel のセルにはタブを入力できないのですが、別のファイルから Excel に変換されている場合などは、タブが入っていることがあります。
しかし、タブを検索しようとしても、検索文字列にタブを入力できず、そのままでは検索できません。
改行の場合は、検索文字列のところに Ctrl + J と入力すれば、検索できるようです(今日初めて知りました ^^;)。
ただし、Ctrl + J は、Chr(10)(LF:ラインフィード)のようで、Chr(13)(CR:キャリッジリターン)は検索できないようです。
手持ちのファイルで、Ctrl + J をスペースに置き換えたのですが、一部の改行が残ってしまいました。
結局、Excel のマクロで改行とタブを半角スペースに置き換えることにしました。
Sub 改行をスペースに置換()
'
Cells.Replace What:=Chr(10), Replacement:=" ", LookAt:=xlPart, _
SearchOrder:=xlByRows, MatchCase:=False, SearchFormat:=False, _
ReplaceFormat:=False
'
Cells.Replace What:=Chr(13), Replacement:=" ", LookAt:=xlPart, _
SearchOrder:=xlByRows, MatchCase:=False, SearchFormat:=False, _
ReplaceFormat:=False
End Sub
Sub タブをスペースに置換()
'
Cells.Replace What:=Chr(9), Replacement:=" ", LookAt:=xlPart, _
SearchOrder:=xlByRows, MatchCase:=False, SearchFormat:=False, _
ReplaceFormat:=False
End Sub
普通、Excel のセルにはタブを入力できないのですが、別のファイルから Excel に変換されている場合などは、タブが入っていることがあります。
しかし、タブを検索しようとしても、検索文字列にタブを入力できず、そのままでは検索できません。
改行の場合は、検索文字列のところに Ctrl + J と入力すれば、検索できるようです(今日初めて知りました ^^;)。
ただし、Ctrl + J は、Chr(10)(LF:ラインフィード)のようで、Chr(13)(CR:キャリッジリターン)は検索できないようです。
手持ちのファイルで、Ctrl + J をスペースに置き換えたのですが、一部の改行が残ってしまいました。
結局、Excel のマクロで改行とタブを半角スペースに置き換えることにしました。
Sub 改行をスペースに置換()
'
Cells.Replace What:=Chr(10), Replacement:=" ", LookAt:=xlPart, _
SearchOrder:=xlByRows, MatchCase:=False, SearchFormat:=False, _
ReplaceFormat:=False
'
Cells.Replace What:=Chr(13), Replacement:=" ", LookAt:=xlPart, _
SearchOrder:=xlByRows, MatchCase:=False, SearchFormat:=False, _
ReplaceFormat:=False
End Sub
Sub タブをスペースに置換()
'
Cells.Replace What:=Chr(9), Replacement:=" ", LookAt:=xlPart, _
SearchOrder:=xlByRows, MatchCase:=False, SearchFormat:=False, _
ReplaceFormat:=False
End Sub
 [0回]
[0回]
PR
昨日の夕方、重たいソフトを立ち上げているせいか、キー入力がなかなか受け付けられない!と思っていたら、夜になって全くキーが聞かなくなり、
「あ、キーボードの電池切れだ」
と気づきました。^^;
以前、電池切れになったときは、ワイヤレスキーボードのアイコンに電池切れの警告表示が付いたと思ったのですが、いつのまにかアイコンが自体がなくなっていました。
何かの設定をしたあと、[終了] をクリックしてしまったのがいけなかったのでしょうか。
ま、ふだん使うソフトではないので良いのですが、電池切れの警告は出してほしかったなぁ、、、と。
仕事が終わった後だったから良かったものの、これが締め切りに追われているときだったら、めっちゃ焦っていますよ、きっと。
とりあえず、常に電池は常備しておきましょう。
「あ、キーボードの電池切れだ」
と気づきました。^^;
以前、電池切れになったときは、ワイヤレスキーボードのアイコンに電池切れの警告表示が付いたと思ったのですが、いつのまにかアイコンが自体がなくなっていました。
何かの設定をしたあと、[終了] をクリックしてしまったのがいけなかったのでしょうか。
ま、ふだん使うソフトではないので良いのですが、電池切れの警告は出してほしかったなぁ、、、と。
仕事が終わった後だったから良かったものの、これが締め切りに追われているときだったら、めっちゃ焦っていますよ、きっと。
とりあえず、常に電池は常備しておきましょう。
[0回]
#今日のテーマは、PDF の透明テキストを削除し、テキスト認識 をやり直す方法です。
修了作品は終わったのですが、実は 1 冊全部を訳したわけではなく、付録部分が残っています。
選択した原著のページ数があまりに多かったので、付録を除く本文のみを修了作品としたのです。
で、、、残りの部分はもういいや、、、と思っていたのですが、せっかくなので、隙間時間にコツコツ訳してみようと思いました。^o^
で、まずは原著の取り込み (スキャン & OCR) からです。
何せ、前回原著の取り込みをしたのは半年以上前のことなので、かなり忘れていました。^^;
しかも、前回、Acrobat の OCR を使ったのですが、その Acrobat をバージョンアップしてしまったため、メニューがわからず、少々とまどいました。
その Acrobat の OCR なのですが、前回はスキャナについていた OCR より Acrobat の OCR の方が良いと思っていたのですが、今回使って見ると、結構、誤認識があります。
英語を指定しているのに、なぜか「th」が「出」と認識されているケースが多いです。;_;
ちょっと調べてみたところ、Acrobat の OCR で「ClearScan」という方式を選択した方が良かったのでは? という気がしました。
ですが、OCR の後、PDF を上書きしてしまったので、認識したテキストデータを削除しないと、OCR をやり直すことができません!
というわけで、認識したテキストデータ (一般に「透明テキスト」と呼ばれるらしいです) を削除して、ClearScan でテキスト認識をやり直しました。
ステップ1:失敗した OCR テキストの削除
1) [ツール] - [保護] - [非表示情報を検索して削除]をクリック
2) 検索が完了したら、[非表示テキスト] を選択して削除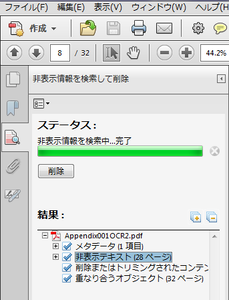
これで、認識したテキストデータが削除されました。
ステップ2: テキスト認識
1) [ツール] - [テキスト認識] で、[このファイル内] を選択
2) [テキスト認識] のポップアップウィンドウで、[編集] をクリック
3) [PDFの出力形式] というプルダウンメニューで、[ClearScan]を選択
4) [OK] をクリック
これで、テキスト認識し直したところ、同じデータなのに誤認識が格段に減りました。
もしかしたら、前回も ClearScan を使ったのかなぁ。。。^^;
修了作品は終わったのですが、実は 1 冊全部を訳したわけではなく、付録部分が残っています。
選択した原著のページ数があまりに多かったので、付録を除く本文のみを修了作品としたのです。
で、、、残りの部分はもういいや、、、と思っていたのですが、せっかくなので、隙間時間にコツコツ訳してみようと思いました。^o^
で、まずは原著の取り込み (スキャン & OCR) からです。
何せ、前回原著の取り込みをしたのは半年以上前のことなので、かなり忘れていました。^^;
しかも、前回、Acrobat の OCR を使ったのですが、その Acrobat をバージョンアップしてしまったため、メニューがわからず、少々とまどいました。
その Acrobat の OCR なのですが、前回はスキャナについていた OCR より Acrobat の OCR の方が良いと思っていたのですが、今回使って見ると、結構、誤認識があります。
英語を指定しているのに、なぜか「th」が「出」と認識されているケースが多いです。;_;
ちょっと調べてみたところ、Acrobat の OCR で「ClearScan」という方式を選択した方が良かったのでは? という気がしました。
ですが、OCR の後、PDF を上書きしてしまったので、認識したテキストデータを削除しないと、OCR をやり直すことができません!
というわけで、認識したテキストデータ (一般に「透明テキスト」と呼ばれるらしいです) を削除して、ClearScan でテキスト認識をやり直しました。
ステップ1:失敗した OCR テキストの削除
1) [ツール] - [保護] - [非表示情報を検索して削除]をクリック
2) 検索が完了したら、[非表示テキスト] を選択して削除
これで、認識したテキストデータが削除されました。
ステップ2: テキスト認識
1) [ツール] - [テキスト認識] で、[このファイル内] を選択
2) [テキスト認識] のポップアップウィンドウで、[編集] をクリック
3) [PDFの出力形式] というプルダウンメニューで、[ClearScan]を選択
4) [OK] をクリック
これで、テキスト認識し直したところ、同じデータなのに誤認識が格段に減りました。
もしかしたら、前回も ClearScan を使ったのかなぁ。。。^^;
[2回]
なんだかんだ言いながら、結局、iPhone を買ってしまいました。^o^
そして、今までスマフォで使っていたカレンダーが使えなくなったので、ジョルテを導入しました。
ついでに、PC でスケジュール管理に使っていた「秘書君」も、Googleカレンダーと同期できるものに置き換えたい、、、と探し、FavGCalScheduler というソフトを見つけました。これは、なかなか良さそうです。
万一に備えて、一応、秘書君も残していますが、たぶん年末までには秘書君ともサヨナラすることになるでしょう。^^;
秘書君は、「昼食をお取りください」とか「もう3時間も働いていますよ」、「働き過ぎは体によくありません」とか声をかけてくれるのが、妙に良かったのですが、やっぱりスケジュールの二重管理は面倒なので、致しかたありません。
たぶん、仕事のスケジュールだけならば、秘書君が一番良いのですが、家族とスケジュールを共有したりするのに、Google カレンダーが便利なんですよね。
秘書君、ごめんなさい。
でも、バージョンアップしてくれたら、また秘書君を採用するかもしれません。^o^
そして、今までスマフォで使っていたカレンダーが使えなくなったので、ジョルテを導入しました。
ついでに、PC でスケジュール管理に使っていた「秘書君」も、Googleカレンダーと同期できるものに置き換えたい、、、と探し、FavGCalScheduler というソフトを見つけました。これは、なかなか良さそうです。
万一に備えて、一応、秘書君も残していますが、たぶん年末までには秘書君ともサヨナラすることになるでしょう。^^;
秘書君は、「昼食をお取りください」とか「もう3時間も働いていますよ」、「働き過ぎは体によくありません」とか声をかけてくれるのが、妙に良かったのですが、やっぱりスケジュールの二重管理は面倒なので、致しかたありません。
たぶん、仕事のスケジュールだけならば、秘書君が一番良いのですが、家族とスケジュールを共有したりするのに、Google カレンダーが便利なんですよね。
秘書君、ごめんなさい。
でも、バージョンアップしてくれたら、また秘書君を採用するかもしれません。^o^
[1回]
今日は久しぶりにサンデー プログラマーしてました。
前から数独というパズルが好きなのですが、先日ふと、これってアルゴリズム的に解くとしたら、どうなるのだろう、、、と思ったのがきっかけで、ちょっと暇になったので、トライしてみました。
最初はVC++で作ろうかと思ったのですが、UIを作るのも面倒なので、Excelのマクロで作ることにしました。
Excelだと表計算と組み合わせて作ることができるので便利です。
↓こんな感じで作っています。
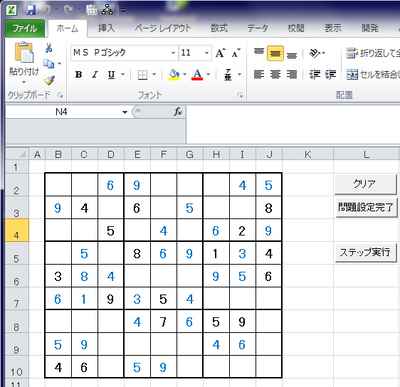
まだ、アルゴリズムのうち3/4しか完成していませんが、初級の問題だと、十分解くことができます。
手順がわかるように、1 ステップずつ実行するように作っているのですが、アルゴリズムはわかっているはずなのに、意外と「あれ? なんでそこがその値になるの?」と思うことがあり、上級問題がなかなか解けない理由がわかった気がします。^o^
このプログラムで簡単に解いてしまおう、なんて気はさらさら無いのですが、上級問題が解けるようになる訓練はできるかもしれません!^^;
前から数独というパズルが好きなのですが、先日ふと、これってアルゴリズム的に解くとしたら、どうなるのだろう、、、と思ったのがきっかけで、ちょっと暇になったので、トライしてみました。
最初はVC++で作ろうかと思ったのですが、UIを作るのも面倒なので、Excelのマクロで作ることにしました。
Excelだと表計算と組み合わせて作ることができるので便利です。
↓こんな感じで作っています。
まだ、アルゴリズムのうち3/4しか完成していませんが、初級の問題だと、十分解くことができます。
手順がわかるように、1 ステップずつ実行するように作っているのですが、アルゴリズムはわかっているはずなのに、意外と「あれ? なんでそこがその値になるの?」と思うことがあり、上級問題がなかなか解けない理由がわかった気がします。^o^
このプログラムで簡単に解いてしまおう、なんて気はさらさら無いのですが、上級問題が解けるようになる訓練はできるかもしれません!^^;
[0回]
