「駆け出しの翻訳屋」として、学習したことをちょこちょこ書くつもりでしたが、「いつまで駆け出しなんだ?!」と言っているうちに早、リタイア年齢に!
現在は、城めぐり、乗り鉄などの旅と読書の話がメインです。
昨日の考察 (?) に基づき、Idiom の翻訳メモリをまとめておきました。
早い話が、同じクライアントからいただいた翻訳キットを展開し直して、1 つの翻訳メモリにインポートしました。
次回からはこの翻訳メモリに追加していく形にします。
ちょっと手間がかかりましたが、2度目に気づいただけマシと考えましょう。。。^^;
問題は、用語集のインポートですね。。。
TBX形式の用語集の作成に失敗したのかと思い、この用語集の拡張子を.tbxにして OmegaT のプロジェクトに入れてみましたが、全く問題なく動作しました。
つまり、TBX形式には問題ないんですよね。。。謎。
早い話が、同じクライアントからいただいた翻訳キットを展開し直して、1 つの翻訳メモリにインポートしました。
次回からはこの翻訳メモリに追加していく形にします。
ちょっと手間がかかりましたが、2度目に気づいただけマシと考えましょう。。。^^;
問題は、用語集のインポートですね。。。
TBX形式の用語集の作成に失敗したのかと思い、この用語集の拡張子を.tbxにして OmegaT のプロジェクトに入れてみましたが、全く問題なく動作しました。
つまり、TBX形式には問題ないんですよね。。。謎。
 [0回]
[0回]
PR
久々に Idiom を使う仕事をしてました。
Idiom は、ちょっと前に一度だけ使ったことがあります。使い方にそれほど悩んだ記憶はなかったのですが、翻訳メモリはうまく検索できないし、タグの中身は確認できないし、、、ちょっととまどいました。
たとえば、用語集にない用語とか、定型的な表現とかを翻訳メモリで検索することがあるのですが、当然ありそうな表現も全くヒットせず。。。
しかも今回スタイルガイドもなかったので、クライアントの HP で表記スタイルや表現を確認して、なんとか仕事を終えました。
作業中はツールの使い方を調べている暇もなかったので、ちょっと力ずくのような、ローテクの作業でしたが、今後のために Idiom の使い方をもう一度調べようと思いました。
しかし、、、調べた結果は、結局、良い方法は無い!ってことでした。^^;
以下、その詳細です。
【翻訳メモリ】
クライアントのところには大量の翻訳メモリがあるはずだと思うのですが、こちらに渡された翻訳キットには、ある程度ヒットした翻訳メモリしか添付されていないらしく、探したところで出てこないという状況でした。
しかも、関連する複数の翻訳キットがあるにも関わらず、プロジェクト毎に関連する翻訳メモリだけが添付されているようです。
これはどうやら、翻訳キットを作成するときの Idiom の仕様のようですね。-.-;
ただし、複数の翻訳メモリを参照することはできるので、関連するプロジェクトの翻訳メモリをすべて追加して作業すれば、「前のプロジェクトの翻訳メモリには、こんな表現があったのに」などということはなさそうです。
というか、、、クライアントごとに翻訳メモリを作成して、プロジェクトを開くときに、既存の翻訳メモリに追加するようにすればよいのかもしれません。
ちなみに、翻訳メモリのインポートや統合機能はないようです。
【タグ】
タグは、[表示] > [タグの表示] で表示されるはずなのに、[タグの表示] というメニューが表示されず、悩んでました。
これは、何のことはない、[アセット プロパティ] で [マークアップの表示] が False になっているためでした。
つまり、クライアント側が翻訳キットを作成するときに、表示不可に設定しているということですね。(なんで?! ;_;)
【用語ベース】
作業を効率化するため、用語集を Idiom の用語ベースに変換しようとしたのですが、TBX 形式の用語ベースを認識はするものの、いざインポートを実行すると、「XCSファイルがない」というエラーなっていまい(このファイルはオプションなのですが?!)、うまくいきませんでした。。。>_<;
あぁ、もう。。。。!!
Idiom は、ちょっと前に一度だけ使ったことがあります。使い方にそれほど悩んだ記憶はなかったのですが、翻訳メモリはうまく検索できないし、タグの中身は確認できないし、、、ちょっととまどいました。
たとえば、用語集にない用語とか、定型的な表現とかを翻訳メモリで検索することがあるのですが、当然ありそうな表現も全くヒットせず。。。
しかも今回スタイルガイドもなかったので、クライアントの HP で表記スタイルや表現を確認して、なんとか仕事を終えました。
作業中はツールの使い方を調べている暇もなかったので、ちょっと力ずくのような、ローテクの作業でしたが、今後のために Idiom の使い方をもう一度調べようと思いました。
しかし、、、調べた結果は、結局、良い方法は無い!ってことでした。^^;
以下、その詳細です。
【翻訳メモリ】
クライアントのところには大量の翻訳メモリがあるはずだと思うのですが、こちらに渡された翻訳キットには、ある程度ヒットした翻訳メモリしか添付されていないらしく、探したところで出てこないという状況でした。
しかも、関連する複数の翻訳キットがあるにも関わらず、プロジェクト毎に関連する翻訳メモリだけが添付されているようです。
これはどうやら、翻訳キットを作成するときの Idiom の仕様のようですね。-.-;
ただし、複数の翻訳メモリを参照することはできるので、関連するプロジェクトの翻訳メモリをすべて追加して作業すれば、「前のプロジェクトの翻訳メモリには、こんな表現があったのに」などということはなさそうです。
というか、、、クライアントごとに翻訳メモリを作成して、プロジェクトを開くときに、既存の翻訳メモリに追加するようにすればよいのかもしれません。
ちなみに、翻訳メモリのインポートや統合機能はないようです。
【タグ】
タグは、[表示] > [タグの表示] で表示されるはずなのに、[タグの表示] というメニューが表示されず、悩んでました。
これは、何のことはない、[アセット プロパティ] で [マークアップの表示] が False になっているためでした。
つまり、クライアント側が翻訳キットを作成するときに、表示不可に設定しているということですね。(なんで?! ;_;)
【用語ベース】
作業を効率化するため、用語集を Idiom の用語ベースに変換しようとしたのですが、TBX 形式の用語ベースを認識はするものの、いざインポートを実行すると、「XCSファイルがない」というエラーなっていまい(このファイルはオプションなのですが?!)、うまくいきませんでした。。。>_<;
あぁ、もう。。。。!!
[0回]
昨日に続いて城攻めの日です。
まずは今治城です。

天守はコンクリートの再建ですが、鉄御門の上の櫓(多聞櫓)は木造で復元されていて、とても見応えがあります。
続いて、丸亀城です。
丸亀城は石垣がみごとなのですが、雨のため、写真は断念しました。

まずは今治城です。
天守はコンクリートの再建ですが、鉄御門の上の櫓(多聞櫓)は木造で復元されていて、とても見応えがあります。
続いて、丸亀城です。
丸亀城は石垣がみごとなのですが、雨のため、写真は断念しました。
[0回]
今日は城攻め&ライブです。
あいにくの雨でしたが、松山城に徒歩で登城しました。

さらに湯築城を攻略。
そして、ひめぎんホールで達郎さんのライブです。
ひめぎんホールは思ったより大きくてびっくりしました。エントランスホールが広くて、開場待ちの列もホール内で並ぶことができます。
中も広くて椅子もゆったり目です。
達郎さんによると、ホールとしては全国で3番目に大きいそうです!
恐るべし、ひめぎん。
あいにくの雨でしたが、松山城に徒歩で登城しました。
さらに湯築城を攻略。
そして、ひめぎんホールで達郎さんのライブです。
ひめぎんホールは思ったより大きくてびっくりしました。エントランスホールが広くて、開場待ちの列もホール内で並ぶことができます。
中も広くて椅子もゆったり目です。
達郎さんによると、ホールとしては全国で3番目に大きいそうです!
恐るべし、ひめぎん。
[0回]
修了作品の続きを翻訳するにあたり、翻訳ツールを OmegaT から Trados 2011 に移行することにしました。
OmegaT は気に入っているのですが、Word の数式の扱いに問題があるためです。
<2013.10.28 追記>
「Word の数式の扱いに問題」という件、私の勘違いで、別のエラーかもしれません。
後で試したら、再現しなかった箇所がありました)。
というわけで、OmegaT から Trados 2011 へのお引っ越しについてまとめました。
1. 翻訳メモリのインポート
OmegaT には翻訳メモリが3種類ありますが、Trados 2011 にエクスポートするのはタグ情報なしの翻訳メモリにします。
つまり、(プロジェクト名)-level1.tmx というファイルです。
Trados 2011へのインポートは簡単でした。
あらかじめ、Trados 2011 で翻訳メモリを作成しておき、そのメモリを選択して、[ファイル]-[インポート] をクリックします。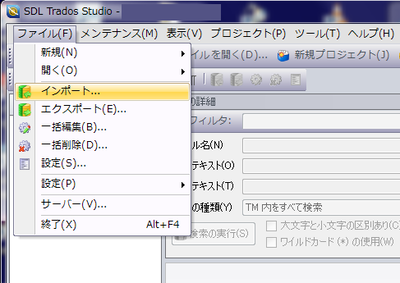 次に、[インポート] ウィンドウで、[ファイルの追加] をクリックして、インポートする翻訳メモリを選択します。
次に、[インポート] ウィンドウで、[ファイルの追加] をクリックして、インポートする翻訳メモリを選択します。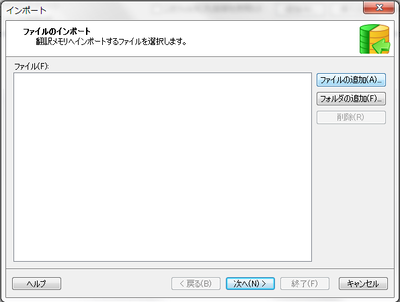 あとは、ウィザードに従うだけです。
あとは、ウィザードに従うだけです。
2. 用語集のインポート
用語集はちょっとだけ手間がかかります。
1) OmegaT の用語集の変換
OmegaT の用語集(タブ区切りの TXT ファイル)を開き、先頭に見出しの行
English<tab>Japanese
を追加します。
文字コードをShiftJISに変更して、別名で保存します。
2) MultiTerm Convert で上記の用語集を変換
まず、[スタート] メニューから [SDL MultiTerm 2011 Convert] を起動します。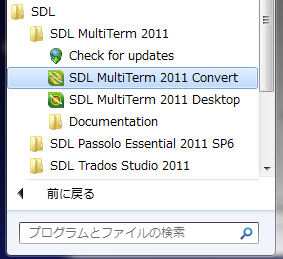 次に、ウィザードに従って、次のように設定します。
次に、ウィザードに従って、次のように設定します。
・[新規変換セッション] を選択して [次へ] をクリック。
・[スプレッドシートまたはデータベース交換形式] を選択して、[次へ] をクリック。
・入力ファイルに、上記でShiftJISに変更した用語集のファイルを選択して設定。
その他の項目は自動で入ったものをそのままとする。[次へ] をクリック。
・区切り文字が [タブ] になっていて、[データプレビュー] が正しく表示されていることを確認して、[次へ]をクリック。
・[見出しフィールド] の [English] を選択して、[インデックス フィールド] の [English (United Staes)]を 選択。
同様に [Japanese] を選択して、[インデックス フィールド] の [Japanese] を選択。
[次へ] をクリック。
・エントリ構造はそのままにして [次へ] をクリック。
・以下、ウィザードに従って [次へ] をクリック。
3) MultiTerm用語ベースにインポート
まず、MultiTerm Desktop を起動し、用語ベースを作成します。
・[用語ベース] - [用語ベースの作成] を選択。
・[既存の用語ベース定義ファイルを読み込み] を選択し、2)の変換でできた.xdtファイルを選択。[次へ]をクリック。
・用語ベースの表示名を設定し、[次へ] をクリック。
・インデックスフィールドに [English] と [Japanese] が表示されていることを確認し、[次へ] をクリック。
・以下、ウィザードに従って [次へ] をクリック。
次に、作成した用語ベースに2)の用語集をインポートします。
・[カタログ] ビューを開く。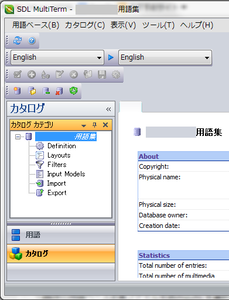 ・[Import] をクリック。
・[Import] をクリック。
・[Default import definition] を選択。
・[カタログ] - [実行] をクリック。
・[インポート ファイル] に2)の変換でできた.xmlファイルを指定して、[次へ] をクリック。
・[除外ファイル] に適当なファイル名を設定して、[次へ] をクリック。
・以下、ウィザードに従って [次へ] をクリック。
OmegaT は気に入っているのですが、Word の数式の扱いに問題があるためです。
<2013.10.28 追記>
「Word の数式の扱いに問題」という件、私の勘違いで、別のエラーかもしれません。
後で試したら、再現しなかった箇所がありました)。
というわけで、OmegaT から Trados 2011 へのお引っ越しについてまとめました。
1. 翻訳メモリのインポート
OmegaT には翻訳メモリが3種類ありますが、Trados 2011 にエクスポートするのはタグ情報なしの翻訳メモリにします。
つまり、(プロジェクト名)-level1.tmx というファイルです。
Trados 2011へのインポートは簡単でした。
あらかじめ、Trados 2011 で翻訳メモリを作成しておき、そのメモリを選択して、[ファイル]-[インポート] をクリックします。
2. 用語集のインポート
用語集はちょっとだけ手間がかかります。
1) OmegaT の用語集の変換
OmegaT の用語集(タブ区切りの TXT ファイル)を開き、先頭に見出しの行
English<tab>Japanese
を追加します。
文字コードをShiftJISに変更して、別名で保存します。
2) MultiTerm Convert で上記の用語集を変換
まず、[スタート] メニューから [SDL MultiTerm 2011 Convert] を起動します。
・[新規変換セッション] を選択して [次へ] をクリック。
・[スプレッドシートまたはデータベース交換形式] を選択して、[次へ] をクリック。
・入力ファイルに、上記でShiftJISに変更した用語集のファイルを選択して設定。
その他の項目は自動で入ったものをそのままとする。[次へ] をクリック。
・区切り文字が [タブ] になっていて、[データプレビュー] が正しく表示されていることを確認して、[次へ]をクリック。
・[見出しフィールド] の [English] を選択して、[インデックス フィールド] の [English (United Staes)]を 選択。
同様に [Japanese] を選択して、[インデックス フィールド] の [Japanese] を選択。
[次へ] をクリック。
・エントリ構造はそのままにして [次へ] をクリック。
・以下、ウィザードに従って [次へ] をクリック。
3) MultiTerm用語ベースにインポート
まず、MultiTerm Desktop を起動し、用語ベースを作成します。
・[用語ベース] - [用語ベースの作成] を選択。
・[既存の用語ベース定義ファイルを読み込み] を選択し、2)の変換でできた.xdtファイルを選択。[次へ]をクリック。
・用語ベースの表示名を設定し、[次へ] をクリック。
・インデックスフィールドに [English] と [Japanese] が表示されていることを確認し、[次へ] をクリック。
・以下、ウィザードに従って [次へ] をクリック。
次に、作成した用語ベースに2)の用語集をインポートします。
・[カタログ] ビューを開く。
・[Default import definition] を選択。
・[カタログ] - [実行] をクリック。
・[インポート ファイル] に2)の変換でできた.xmlファイルを指定して、[次へ] をクリック。
・[除外ファイル] に適当なファイル名を設定して、[次へ] をクリック。
・以下、ウィザードに従って [次へ] をクリック。
[0回]
