駆け出しの翻訳屋といいながら早数年。
学習したことをちょこちょこ書くつもりでしたが、最近は余暇の話が多いような。。。
そもそも、いつまで駆け出しなんだ?!
#今日のテーマは、PDF の透明テキストを削除し、テキスト認識 をやり直す方法です。
修了作品は終わったのですが、実は 1 冊全部を訳したわけではなく、付録部分が残っています。
選択した原著のページ数があまりに多かったので、付録を除く本文のみを修了作品としたのです。
で、、、残りの部分はもういいや、、、と思っていたのですが、せっかくなので、隙間時間にコツコツ訳してみようと思いました。^o^
で、まずは原著の取り込み (スキャン & OCR) からです。
何せ、前回原著の取り込みをしたのは半年以上前のことなので、かなり忘れていました。^^;
しかも、前回、Acrobat の OCR を使ったのですが、その Acrobat をバージョンアップしてしまったため、メニューがわからず、少々とまどいました。
その Acrobat の OCR なのですが、前回はスキャナについていた OCR より Acrobat の OCR の方が良いと思っていたのですが、今回使って見ると、結構、誤認識があります。
英語を指定しているのに、なぜか「th」が「出」と認識されているケースが多いです。;_;
ちょっと調べてみたところ、Acrobat の OCR で「ClearScan」という方式を選択した方が良かったのでは? という気がしました。
ですが、OCR の後、PDF を上書きしてしまったので、認識したテキストデータを削除しないと、OCR をやり直すことができません!
というわけで、認識したテキストデータ (一般に「透明テキスト」と呼ばれるらしいです) を削除して、ClearScan でテキスト認識をやり直しました。
ステップ1:失敗した OCR テキストの削除
1) [ツール] - [保護] - [非表示情報を検索して削除]をクリック
2) 検索が完了したら、[非表示テキスト] を選択して削除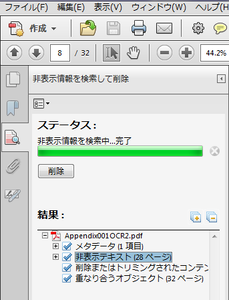
これで、認識したテキストデータが削除されました。
ステップ2: テキスト認識
1) [ツール] - [テキスト認識] で、[このファイル内] を選択
2) [テキスト認識] のポップアップウィンドウで、[編集] をクリック
3) [PDFの出力形式] というプルダウンメニューで、[ClearScan]を選択
4) [OK] をクリック
これで、テキスト認識し直したところ、同じデータなのに誤認識が格段に減りました。
もしかしたら、前回も ClearScan を使ったのかなぁ。。。^^;
修了作品は終わったのですが、実は 1 冊全部を訳したわけではなく、付録部分が残っています。
選択した原著のページ数があまりに多かったので、付録を除く本文のみを修了作品としたのです。
で、、、残りの部分はもういいや、、、と思っていたのですが、せっかくなので、隙間時間にコツコツ訳してみようと思いました。^o^
で、まずは原著の取り込み (スキャン & OCR) からです。
何せ、前回原著の取り込みをしたのは半年以上前のことなので、かなり忘れていました。^^;
しかも、前回、Acrobat の OCR を使ったのですが、その Acrobat をバージョンアップしてしまったため、メニューがわからず、少々とまどいました。
その Acrobat の OCR なのですが、前回はスキャナについていた OCR より Acrobat の OCR の方が良いと思っていたのですが、今回使って見ると、結構、誤認識があります。
英語を指定しているのに、なぜか「th」が「出」と認識されているケースが多いです。;_;
ちょっと調べてみたところ、Acrobat の OCR で「ClearScan」という方式を選択した方が良かったのでは? という気がしました。
ですが、OCR の後、PDF を上書きしてしまったので、認識したテキストデータを削除しないと、OCR をやり直すことができません!
というわけで、認識したテキストデータ (一般に「透明テキスト」と呼ばれるらしいです) を削除して、ClearScan でテキスト認識をやり直しました。
ステップ1:失敗した OCR テキストの削除
1) [ツール] - [保護] - [非表示情報を検索して削除]をクリック
2) 検索が完了したら、[非表示テキスト] を選択して削除
これで、認識したテキストデータが削除されました。
ステップ2: テキスト認識
1) [ツール] - [テキスト認識] で、[このファイル内] を選択
2) [テキスト認識] のポップアップウィンドウで、[編集] をクリック
3) [PDFの出力形式] というプルダウンメニューで、[ClearScan]を選択
4) [OK] をクリック
これで、テキスト認識し直したところ、同じデータなのに誤認識が格段に減りました。
もしかしたら、前回も ClearScan を使ったのかなぁ。。。^^;
 [2回]
[2回]
PR
この記事にコメントする
カレンダー
| 12 | 2026/01 | 02 |
| S | M | T | W | T | F | S |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 7 | 8 | 9 | 10 | |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
カテゴリー
最新コメント
[12/27 Rgo365]
[06/02 Cloudcounty.org]
[05/29 Circajewelry.com]
[05/22 Togel idn]

[03/31 ハルリン]
プロフィール
HN:
明風
性別:
非公開
自己紹介:
技術屋から翻訳屋に転身しようと、退職。
とりあえず、安定して翻訳の仕事を貰えるようになりましたが、まだまだ駆け出しです。胸をはって「翻訳家です」と言えるまで、日夜修行中(?)の身です。
趣味は音楽鑑賞と城めぐり。月平均 1 回以上のライブと登城がエネルギー源です!
とりあえず、安定して翻訳の仕事を貰えるようになりましたが、まだまだ駆け出しです。胸をはって「翻訳家です」と言えるまで、日夜修行中(?)の身です。
趣味は音楽鑑賞と城めぐり。月平均 1 回以上のライブと登城がエネルギー源です!
最新記事
(01/06)
(12/31)
(10/23)
(10/06)
(09/12)
バーコード
ブログ内検索
P R
忍者AdMax
フリーエリア